@TheTuringPost: Good answers follow good reaso...
@TheTuringPost
13 views
Jun 01, 2025
1
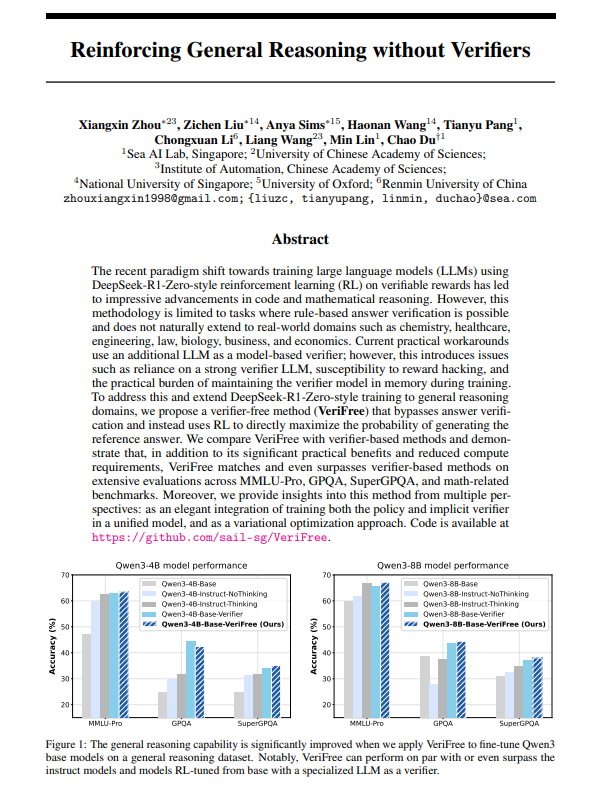
Good answers follow good reasoning
VeriFree is a new method that keeps the benefits of reinforcement learning (RL) but gets rid of a verifier model and rule-based checking.
It trains the model to get closer to a known good answer, called a reference answer.
Benefits:
• It's faster and simpler
• Requires less compute
• Is more stable
Here's how VeriFree works🧵
VeriFree is a new method that keeps the benefits of reinforcement learning (RL) but gets rid of a verifier model and rule-based checking.
It trains the model to get closer to a known good answer, called a reference answer.
Benefits:
• It's faster and simpler
• Requires less compute
• Is more stable
Here's how VeriFree works🧵
2
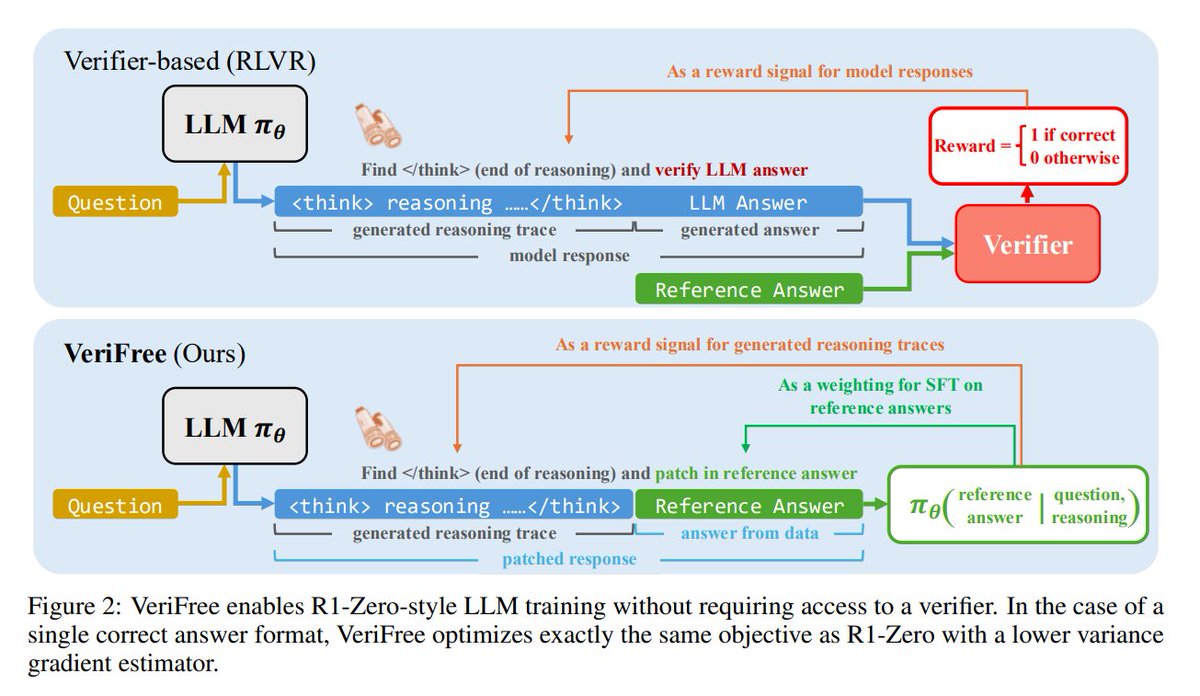
1. Step-by-step VeriFree workflow:
• The model generates a reasoning trace.
• The final answer isn't checked directly.
• Instead, it's checked how likely the model is to generate the correct answer based on its reasoning.
• That likelihood becomes the reward. It's higher if the model seems confident in the correct answer.
• The model generates a reasoning trace.
• The final answer isn't checked directly.
• Instead, it's checked how likely the model is to generate the correct answer based on its reasoning.
• That likelihood becomes the reward. It's higher if the model seems confident in the correct answer.
3
2. Smart tokenization:
Splitting the model’s response into <reasoning> and <answer> needs to be done carefully.
Instead of splitting at "<answer>", researchers decided stop at "<answer" without the closing bracket. This avoids token mismatches and keeps training stable.
Splitting the model’s response into <reasoning> and <answer> needs to be done carefully.
Instead of splitting at "<answer>", researchers decided stop at "<answer" without the closing bracket. This avoids token mismatches and keeps training stable.
4
3. VeriFree's working process also allows to train the model using just one correct answer per question, without needing to generate and verify each possible answer during training.
5
4. Why is VeriFree more stable?
It skips sampling the final answer — the system just calculates the chance the model would say the right thing. This removes randomness and makes the learning process more efficient.
It skips sampling the final answer — the system just calculates the chance the model would say the right thing. This removes randomness and makes the learning process more efficient.

6
VeriFree reinforces answers that follow good reasoning. If the reasoning is off, the training signal gets weaker. This helps the model learn to reason better, not just guess answers.
Paper: arxiv.org/abs/2505.21493
Code: github.com/sail-sg/VeriFr…
Paper: arxiv.org/abs/2505.21493
Code: github.com/sail-sg/VeriFr…