@omarsar0: LLMs Get Lost in Multi-turn Co...
@omarsar0
9 views
Jun 06, 2025
1
LLMs Get Lost in Multi-turn Conversation
The cat is out of the bag.
Pay attention, devs.
This is one of the most common issues when building with LLMs today.
Glad there is now paper to share insights.
Here are my notes:
The cat is out of the bag.
Pay attention, devs.
This is one of the most common issues when building with LLMs today.
Glad there is now paper to share insights.
Here are my notes:

2
The paper investigates how LLMs perform in realistic, multi-turn conversational settings where user instructions are often underspecified and clarified over several turns.
I keep telling devs to spend time preparing those initial instructions. Prompt engineering is important.
I keep telling devs to spend time preparing those initial instructions. Prompt engineering is important.

3
The authors conduct large-scale simulations across 15 top LLMs (including GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, Deepseek-R1, and others) over six generation tasks (code, math, SQL, API calls, data-to-text, and document summarization).

4
Severe Performance Drop in Multi-Turn Settings
All tested LLMs show significantly worse performance in multi-turn, underspecified conversations compared to single-turn, fully-specified instructions.
The average performance drop is 39% across six tasks, even for SoTA models. For example, models with >90% accuracy in single-turn settings often drop to ~60% in multi-turn settings.
All tested LLMs show significantly worse performance in multi-turn, underspecified conversations compared to single-turn, fully-specified instructions.
The average performance drop is 39% across six tasks, even for SoTA models. For example, models with >90% accuracy in single-turn settings often drop to ~60% in multi-turn settings.

5
Degradation Is Due to Unreliability, Not Just Aptitude
The performance loss decomposes into a modest decrease in best-case capability (aptitude, -15%) and a dramatic increase in unreliability (+112%).
In multi-turn settings, the gap between the best and worst response widens substantially, meaning LLMs become much less consistent and predictable.
High-performing models in single-turn settings are just as unreliable as smaller models in multi-turn dialogues. Don't ignore testing and evaluating in multi-turn settings.
The performance loss decomposes into a modest decrease in best-case capability (aptitude, -15%) and a dramatic increase in unreliability (+112%).
In multi-turn settings, the gap between the best and worst response widens substantially, meaning LLMs become much less consistent and predictable.
High-performing models in single-turn settings are just as unreliable as smaller models in multi-turn dialogues. Don't ignore testing and evaluating in multi-turn settings.

6
Main reasons LLMs get "lost"
- Make premature and often incorrect assumptions early in the conversation.
- Attempt full solutions before having all necessary information, leading to “bloated” or off-target answers.
- Over-rely on their previous (possibly incorrect) answers, compounding errors as the conversation progresses.
- Produce overly verbose outputs, which can further muddle context and confuse subsequent turns.
- Pay disproportionate attention to the first and last turns, neglecting information revealed in the middle turns (“loss-in-the-middle” effect).
- Make premature and often incorrect assumptions early in the conversation.
- Attempt full solutions before having all necessary information, leading to “bloated” or off-target answers.
- Over-rely on their previous (possibly incorrect) answers, compounding errors as the conversation progresses.
- Produce overly verbose outputs, which can further muddle context and confuse subsequent turns.
- Pay disproportionate attention to the first and last turns, neglecting information revealed in the middle turns (“loss-in-the-middle” effect).

7
Task and Model Agnostic:
The effect is robust across model size, provider, and task type (except for truly episodic tasks, like translation, where multi-turn does not introduce ambiguity).
Even extra test-time reasoning (as in "reasoning models" like o3, Deepseek-R1) does not mitigate the degradation.
I've seen this. I was talking about this in our office hour today, based on observations using Deep Research.
The effect is robust across model size, provider, and task type (except for truly episodic tasks, like translation, where multi-turn does not introduce ambiguity).
Even extra test-time reasoning (as in "reasoning models" like o3, Deepseek-R1) does not mitigate the degradation.
I've seen this. I was talking about this in our office hour today, based on observations using Deep Research.
8
Agentic and System-Level Fixes Are Only Partially Effective:
Recap and “snowball” strategies (where the system repeats all previous user instructions in each turn) partially reduce the performance drop, but don’t fully restore single-turn reliability.
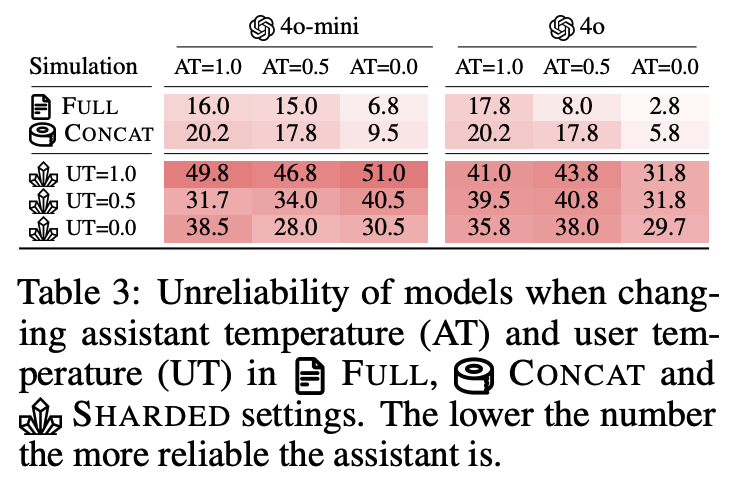
Lowering generation randomness (temperature) also has a limited effect; unreliability persists even at T=0.
Good context management and memory solutions play an important role here.
Recap and “snowball” strategies (where the system repeats all previous user instructions in each turn) partially reduce the performance drop, but don’t fully restore single-turn reliability.
Lowering generation randomness (temperature) also has a limited effect; unreliability persists even at T=0.
Good context management and memory solutions play an important role here.
9
Practical Recommendations:
Users are better off consolidating all requirements into a single prompt rather than clarifying over multiple turns.
If a conversation goes off-track, starting a new session with a consolidated summary leads to better outcomes.
System builders and model developers are urged to prioritize reliability in multi-turn contexts, not just raw capability. This is especially true if you are building complex agentic systems where the impact of these issues is more prevalent.
LLMs are really weird. And all this weirdness is creeping up into the latest models too but it more subtle ways. Be careful out there, devs.
More insights and paper here: arxiv.org/abs/2505.06120
Users are better off consolidating all requirements into a single prompt rather than clarifying over multiple turns.
If a conversation goes off-track, starting a new session with a consolidated summary leads to better outcomes.
System builders and model developers are urged to prioritize reliability in multi-turn contexts, not just raw capability. This is especially true if you are building complex agentic systems where the impact of these issues is more prevalent.
LLMs are really weird. And all this weirdness is creeping up into the latest models too but it more subtle ways. Be careful out there, devs.
More insights and paper here: arxiv.org/abs/2505.06120
10
I am going to go over this paper and what it means for devs building with LLMs and agentic systems. It will be available to our academy members here: dair-ai.thinkific.com