@akshay_pachaar: Don't do RAG!Imagine loading...
@akshay_pachaar
26 views
Jan 12, 2025
1
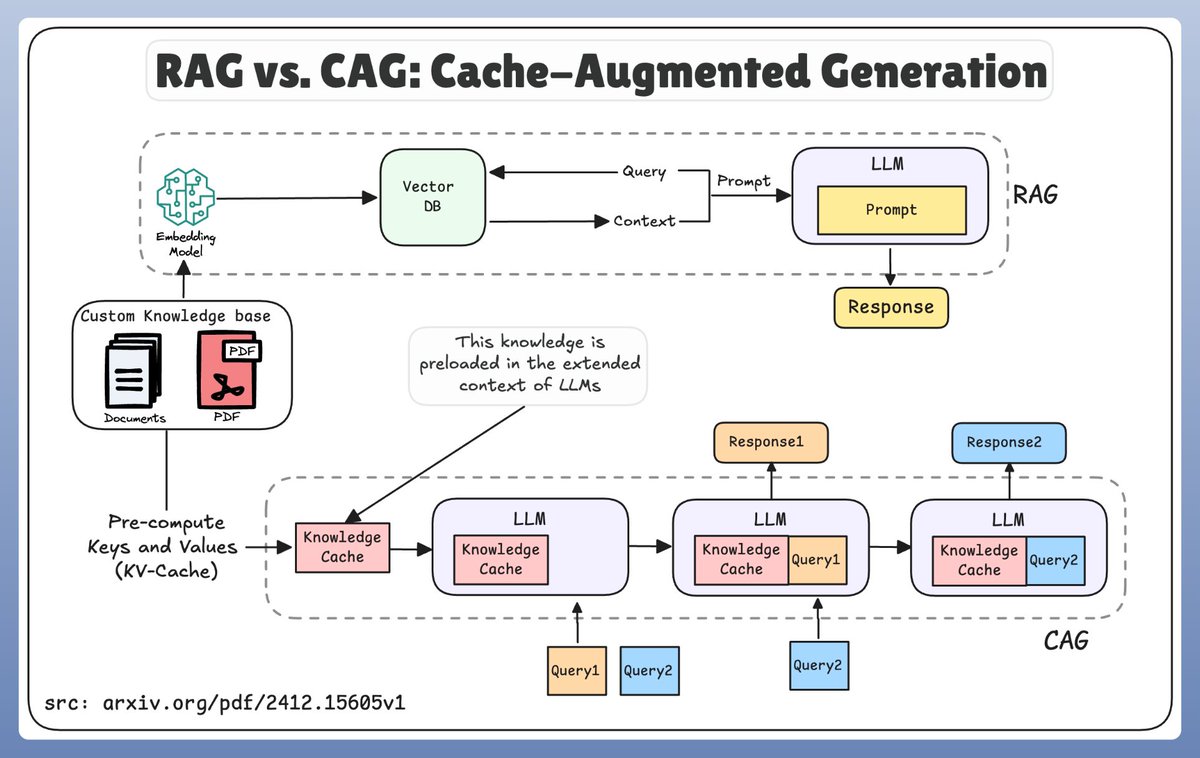
Don't do RAG!
Imagine loading all the relevant documents into your model before you ask a single question—no more waiting on real-time retrieval or dealing with complicated retrieval pipelines.
This is precisely what CAG does, and it does so remarkably well!
The core idea is to replace real-time document retrieval with preloaded knowledge in the extended context of LLMs. This approach ensures faster, more accurate, and consistent generation by avoiding retrieval errors and latency.
(refer the image below as you read)
Key advantages:
↳ No Latency: All data is preloaded, so there’s no waiting for retrieval.
↳ Fewer Mistakes: Precomputed KV-cache avoids ranking or document selection errors.
↳ Simpler Architecture: No separate retriever—just load the cache and go.
↳ Faster Inference: Once cached, responses come at lightning speed.
↳ Higher Accuracy: The model processes a unified, complete context upfront.
But it also has two major limitations:
- Inflexibility to Dynamic Data
- Constrained by Context Length of LLM
Hope you enjoyed reading!
For those who want to dig more, I've shared link to the CAG paper in next tweet!
_____
Find me → @akshay_pachaar ✔️
For more insights & tutorials on AI and Machine Learning.
Imagine loading all the relevant documents into your model before you ask a single question—no more waiting on real-time retrieval or dealing with complicated retrieval pipelines.
This is precisely what CAG does, and it does so remarkably well!
The core idea is to replace real-time document retrieval with preloaded knowledge in the extended context of LLMs. This approach ensures faster, more accurate, and consistent generation by avoiding retrieval errors and latency.
(refer the image below as you read)
Key advantages:
↳ No Latency: All data is preloaded, so there’s no waiting for retrieval.
↳ Fewer Mistakes: Precomputed KV-cache avoids ranking or document selection errors.
↳ Simpler Architecture: No separate retriever—just load the cache and go.
↳ Faster Inference: Once cached, responses come at lightning speed.
↳ Higher Accuracy: The model processes a unified, complete context upfront.
But it also has two major limitations:
- Inflexibility to Dynamic Data
- Constrained by Context Length of LLM
Hope you enjoyed reading!
For those who want to dig more, I've shared link to the CAG paper in next tweet!
_____
Find me → @akshay_pachaar ✔️
For more insights & tutorials on AI and Machine Learning.
2
CAG paper: arxiv.org/pdf/2412.15605…
_____
Interested in ML/AI Engineering? Sign up for our newsletter for in-depth lessons and get a FREE eBook with 150+ core DS/ML lessons: join.dailydoseofds.com
_____
Interested in ML/AI Engineering? Sign up for our newsletter for in-depth lessons and get a FREE eBook with 150+ core DS/ML lessons: join.dailydoseofds.com